
AI下半场哨声吹起,出版行业还要继续观望吗?

从概念狂飙到工程兑现,2025年的生成式人工智能应用明显正在进入“下半场”——成本曲线下探,产品强调场景与应用,舆论也开始从情绪叙事转向对真实场景的冷静评估。那么,出版业还要继续观望吗?
如果上面这些变化仍发生在出版行业的外围,那么在过去半年里,全球范围内大模型公司与出版企业间的一桩桩著作权官司,则引发了出版行业的普遍危机感——出版与AI的共存与融合并不是一个简单的议题。著作权益的边界会否被重新划定?在切实获得技术加持的同时,出版行业会不会连自己的立身之本都难保?
要回答这些问题,我们不妨把镜头推向一个重要的样本:过去25年间,励讯集团(RELX)印刷出版收入占比从64%骤降至4%,而其数字化业务收入占比如今高达84%——该集团长期被视作全球出版行业数字化转型最成功的案例之一。他们能不能为中国同仁提供直面AI议题的新视角?
答案或许是肯定的。励讯集团在2025年上半年披露:集团营收增长7%、营业利润增长9%;首席执行官Erik Engstrom在财报中评价:公司长期增长轨迹的改善正是由于“将强大的人工智能等技术融入了我们的领先内容和数据”。
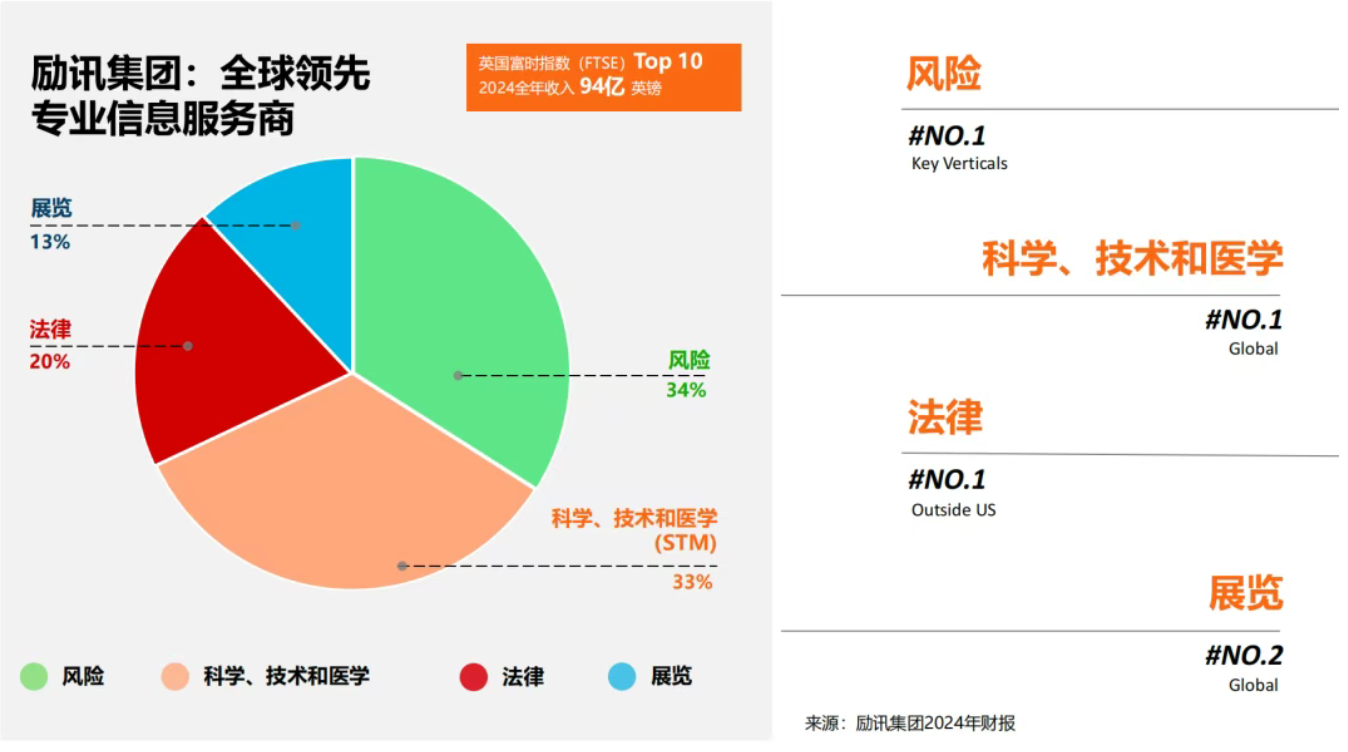
而作为长期关注AI的行业推动者,励讯集团中国区高级副总裁张玉国则在这轮技术洪流大幕拉起之时,就反复提醒出版同行:不要成为AI的“信仰派”或“恐惧派”,而要在真实问题上做出可度量的改进,找到出版行业在AI时代真正的解决方案。
人工智能究竟会给出版行业带来怎样的变革与挑战?在这条赛道上,励讯集团找到了怎样的操作路线与应用场景?出版人手中的版权内容将怎样发挥其真正的作用?当“下半场”的哨声响起,自称“理性乐观派”的资深出版人张玉国,给出了他的全方位观察与思考。
做AI时代的理性乐观派:
看到挑战,更看到机会
《出版人》:在过去几年里,生成式人工智能持续在出版行业中引发讨论,也带来了很多情绪的激荡。在探讨与AI相关的一系列话题前,我觉得心态也是很重要的议题——在今天,出版人究竟应以什么样的心态面对AI?
张玉国:我一直强调,在AI时代,我们要做“理性乐观派”。
现在舆论场很喧嚣,可以看到两派极端:一派是AI信仰派,把AI当作“像上帝一样的技术”,把它神化;在“信仰”的语境里是没有讨论空间的,凡事都被说成革命与颠覆,这是非理性的。另一派是AI恐惧派,认为“硅基文明将取代碳基文明”,人类会被AI取代——这些其实都是science fiction,是科幻叙事。
对此李飞飞教授有一句很经典的论断:science but not science fiction——科学,但不要变成科幻。我们不要总谈“信仰”,也无需深陷“恐惧”。出版界的人,可以更理性,也有足够的理由乐观。
先说“乐观”。我是对技术非常乐观的人,励讯集团的整体风格也如此。为什么要乐观?回看人类文明的发展,基本都跟技术的出现与迭代密切相关:旧石器、新石器,本质上就是按工具与技术来划分时代;此后还有农业革命、蒸汽机时代、电力时代、信息时代……人类文明史本来就是由技术的更迭来命名与推动的。我们今天生活的点点滴滴,也几乎都是由技术塑造的。技术与人从来都是共生的,对于未来,着实没有悲观的必要。
同时我们必须要“理性”。不要当“信仰派”,也不要当“恐惧派”,更不要被热点与炒作带偏。其实AI也不是个新东西,在它近70 年的历史里,和今天类似的“高潮”已经发生过两次,两次高潮之后,随之而来的就是AI寒冬。
上一次AI寒冬离我们不算远,就在20世纪90年代,那时很多博士生毕业的时候,都不敢在简历里写“人工智能”这几个字,怕找不到工作。李开复1998年创办微软亚洲研究院时也是一样——那时只要提“人工智能”,都会被视为“大忽悠”。于是他们在确定研究方向时刻意回避“人工智能”这个词,将其改写为“自然语言处理”“模式识别”“计算机视觉”“机器翻译”等。
为什么会出现这样的问题?归根到底,就是被炒作起来的许多承诺,最后实现不了,政府不再支持,产业资金抽走,学术界的研究经费也随之减少,于是“一落千丈”,进入冬天。不得不说,人类的记忆周期确实很短,二十多年前发生过的事,今天很多人都忘了。所以对眼下的AI热潮,我更希望它不要重蹈覆辙,不要再走一遍“炒作—失望—寒冬”的循环,而要尽快在真实场景里做出真正有用的应用,去帮助社会解决问题。
乐观,是承认技术能带来长期红利;理性,是拒绝神化与恐惧,回到问题本身。AI该做的,是在真实的行业痛点上创造价值、提升效率,而不是被“热点叙事”牵着走。这就是我所说的“AI时代的理性乐观派”。
《出版人》:如果把视角收缩到出版与信息服务行业,您如何判断这一轮生成式AI带来的机遇与挑战?哪些是可以立刻抓住的机会,哪些又是必须直面的难题?
张玉国:我的总体判断是——机遇大于挑战。而且首先要看到机遇。
原因很直接:大模型在自然语言处理上取得了突破,而出版界处理的正是数据内容信息。从这个意义上说,生成式AI天然就是我们行业的工具。这也解释了为什么励讯集团在不到两年的时间里已经推出了超过二十个生成式AI产品——我们做了准备,也确实把这项技术落在信息与分析领域的具体场景里。
所以请先看到机遇。我们的核心竞争力是什么?就是生产高质量、可信赖的内容。这是出版的看家本领,也是我们拥抱AI,把它用好、用稳的底气所在。
当然,我们也要清醒地看到挑战:
第一是机器幻觉。这几乎是首要挑战。它源自技术本质——机器学习遵循“概率近似”原则:总会有概括不到和推测错误的地方,所以只能控制,难以根除。要想把幻觉尽量压下来,路径主要有两条:其一是高质量、可信赖的内容语料;其二是持续的人为微调与对齐——把在互联网泥沙俱下的环境中训练出的那头大模型“怪物”,通过反复校正,磨成一个“小笑脸”,让它吐出更符合人类要求的内容。
第二是虚假信息。2024年全球有大量国家发生重要选举,社会对生成式AI扩散虚假信息影响选民决策的担忧非常强烈,这不是短时间内能完全解决的问题,各国监管部门也都在高度关注这一问题。
第三是能源消耗。关于生成式AI能耗的研究有很多,其能耗水平已经引发社会讨论。我们一方面承认“技术总体能耗”是现代文明要付出的成本;另一方面也要保持怀疑:若仅一项技术就带来巨大能耗,这是否可持续?我对这点保持审慎乐观的态度。
第四是大家经常谈的所谓“AI越狱”问题。人为规训后的大模型理论上知道哪些问题不该回答;但现实里有人通过提示词“绕过”这些限制,让模型给出本不应给出的内容。一个典型例子就是所谓“祖母问题”——借助情境化叙事,诱使模型输出本应受限的危险信息。这提醒我们:“安全对齐”是一项持续工程,不能掉以轻心。
《出版人》:在这四点挑战中,和出版行业关系最密切的是否就是机器幻觉的问题?出版业能提供减少幻觉的工具和方法吗?
张玉国:幻觉对所有的生成式AI来说都算是头号挑战。但为什么我又说它既是挑战又是机遇,是因为专业出版恰好具备两样能有效减少幻觉的东西:
第一,大模型的底座内容必须是“高质量、可信赖”的。出版行业手里已经掌握了大量高质量、可信赖的内容,这是降低幻觉最重要的要素。用“干净”的内容去训练、对齐,和用互联网上“泥沙俱下”的素材训练,效果完全不同。
第二,是检索增强生成(RAG)。其做法很直观:在大模型吐出答案之前,先外挂权威的高质量数据库,让它先去“问一问”、匹配一下;如果不匹配,就引用数据库里更靠谱的内容再组织输出。现在所有做AI的公司想要降低幻觉,基本都要沿着这两条方向去努力。
当然以上我说到的所有挑战,并非都能直接转化为出版业的机遇;它们更多是AI作为通用技术对全社会形成的难题。对出版而言,除了破除幻觉这条与我们的强项直接相关之外,更重要的还是抓住这轮技术红利的核心机会。
这一次的生成式AI主要处理自然语言,而出版的核心竞争力在于处理信息、数据、内容的能力,尤其在专业出版领域。在已有高质量内容的基础上叠加AI工具,我们就能开发出新的生产力,显著提升专业人员的工作效率。我认为,这就是它给出版带来的最核心机遇。
《出版人》:回到励讯集团自身——AI在你们的业务演进里,究竟处在什么位置?
张玉国: AI在一定程度上加速了励讯集团“P→E→S”的战略。
我在励讯集团已经19年,亲历了这条发展主线:从P(Publishing:出版),到E(Electronic Publishing:电子化),再到S(Solution:解决方案)。如果让我给生成式AI下一个判断,我会说:它是我们迈向“S”(解决方案) 过程中的一朵小小的浪花,但没有起到决定性的作用。
我自己每天都在用生成式AI,但主要还是用来搜索。像百度、Google,现在都已经内嵌了AI工具。传统搜索是你输入关键词,它给你吐出二十个网页、五万篇文献,你得一个个点进去看是否匹配;AI加持之后,它可以先给你一个“归纳总结过的答案”,这就是它目前最普遍的应用场景。放眼各行各业,整个生成式AI领域也还没出现一款“杀手级应用”。所以我一直提醒大家:不要神化生成式AI,不要把它夸大。
对励讯集团而言,生成式AI确实推动了“解决方案化”,但仍是一朵浪花。在这一领域,集团在迅速布局;但就现阶段来讲,还看不到它对整体收入有“多大占比”的巨大贡献,至少在财报层面是这样。
《出版人》:站在专业出版和信息分析的场景里,生成式AI究竟解决了什么问题?它和以往的“数字化工具”相比,哪里发生了本质变化?
张玉国:如果归纳生成式AI在我们这个行业的作用,我更愿意归结成“CDST”四个关键词:
C是Conversation——对话式。以前我们获取解决方案,要输入关键词、自己点开一页页结果;现在是直接用自然语言发问,甚至语音就行。生成式AI的革命性,就在于它听得懂自然语言,我们可以直接“问”,这极大降低了获取信息的门槛。
D是Drafting——起草与生成。这也是新能力。过去我们使用的AI大多是提取式:它可以从海量信息里摘取片段,但缺乏整合的能力;现在的生成式AI是真正能“写”——几百字、几千字、几万字,都能起草、续写、改写。
S是Summarization——总结与提炼。这个同样非常有用。大家都忙,时间都很宝贵,因此在长文档中快速抓要点,在专业场景里意义很大。
T是Translation——翻译。这项能力并非生成式AI才有;但有了生成式AI之后,翻译的效率与准确度无疑又往前走了一大步。
所以,返回我们的专业信息分析语境,生成式AI“千变万化”,基本脱离不开这四个功能。它不是神话,也不用神化,本质就是用“CDST” 的四个功能服务专业人员。
《出版人》:在生成式AI崛起之前,励讯内部其实已经有很多基于人工智能的工具在服务用户了。生成式AI会构成对这些“老工具”的冲击吗?
张玉国:励讯集团应用AI已经有十几年了,但当时不是生成式,而是提取式。举个典型例子——推荐机制:一个科研人员进入我们的旗舰数据库看了一篇论文,后台会基于他的学术背景、检索关键词、正在阅读的这篇论文等要素,自动推荐大约50篇相关文献。这和你在视频播放平台看完一部电影,平台再给你推荐20部相关影片是一个逻辑。它看起来不起眼,但其实是非常关键的AI应用,构成了今天绝大多数信息平台获取内容的底层逻辑,而且带来了可观的收入。
至于生成式和提取式两者的关系,我认为不是“完全替代”。生成式AI是一条新的技术路线——它能够“生成”,而过去的提取式AI只能“提取/聚合”——这确实是新增能力,但它不会革提取式AI的命。后者的应用依然会长期存在,而且科研人员每天都在用,包括推荐、摘要、可视化等。生成式AI只是增加了一个“新层”,而且偏重人机交互。如果看科研人员的实际使用次数占比,提取式AI可能还更大一些。
《出版人》:“数字化转型”的口号,我们也喊了很多年。从励讯集团的经验来看,是否只有在完成了足够充分的数字化准备之后,才可能进一步走向“解决方案化/应用化”?
张玉国:没错。第一步必须实现数字化:把写在纸上的一切都变成0和1,存到计算机里。否则这些内容无法被AI利用。只有做到了这一点,内容才能真正变成数据,我们才有资格谈下一步的解决方案。
但这里还有一个核心原则:以客户为中心。我们做的是专业出版信息与分析服务,最终要回答的问题是:你的产品为专业人士解决了什么问题?痛点是什么,怎么被解决?这跟“报个项目、拿点补贴”完全不是一回事;我也绝不提倡做一个“看上去很美”,但结果并没有真正解决专业人士问题的项目。
所以,这场转型本质上是C端驱动的。尽管励讯集团是to B的企业,但我们的产品最终使用者仍然在C端——只是这个“C”是专业用户,包括科研人员、医生、律师等。
《出版人》:对国内的出版机构而言,励讯集团的模式是否可以复制?我们有哪些切入这条赛道的可能性?
张玉国:我相信,一个专业出版商并不一定要依赖AI技术公司把产品都替你做出来。我们这两年的实践给我的体会是:把“大模型”落到“窄域的小模型”,在垂直、专业的赛道里去做,这样做出来的东西更靠谱、更有价值,是真正提高生产力与效率的关键工具。
每一家出版社都可以这么做。一些专业社长期积累了大量高质量、可信赖的内容。那么它们就完全可以从专业痛点出发,把大模型“引进来+小范围适配”,在授权合规的前提下,用自己的高质量语料去做小模型微调,让它在我们熟悉的专业场景里把效率和价值提升起来。
《出版人》:在AI快速发展的过程中,出版业普遍担心大模型训练环节滥用,甚至非法使用出版方的版权内容。您怎么看这类担忧?
张玉国:就生成式AI与版权,现在争议最大的有两个问题。
第一个问题是:AI生成物到底算不算“作品”,能不能被版权法保护?这个存在一定争议——司法界、产业界、艺术界都在讨论。中国已有对此的相关判例;美国版权局也向产业界多次征求意见,并形成了文献综述,最后汇总的观点是:现有版权框架并没有被打破,不必急于另立“AI专门法”去回答“AI生成内容是否受保护”的问题。
这其实不难理解——首先仅靠反复调整提示词,不足以产生可被保护的“原创性”内容;其次按照现有的著作权法规,著作权的权利主体是自然人,我们不会把著作权授予一个“工具”。还有学者强调:同一提示词发给不同的旗舰模型,生成结果并不一致,也就是说人类无法完全控制生成物,那就很难据此认定它可以被版权保护。
第二个问题,也是我个人更关注的:训练数据究竟是否需要获得授权,来源是否应当透明?出版方如何保护自身的著作权不被侵害?过去一年我做了二十多场演讲,基本都在谈这个问题,用一句最简单的话来解释,那便是“皮之不存,毛将焉附。”生成式AI之所以能生成让人眼前一亮的东西,是因为人类已经创造了庞大的知识与作品——没有这些,它是不能凭空产生内容的。那作为大模型的开发者,你不能“吃权利人的饭、砸权利人的碗”,对吧?我们做出版的平时不太用这么重的词,但我确实觉得:要珍视人类创造的这些成果,这是生成式AI模型训练的一个非常关键的前提。
《出版人》:从更宏观的角度看,怎么把这个“度”把握好?既推进技术进步,又不伤害版权生态?
张玉国:这是一个“利益平衡”的问题。引用一位在AI时代积极倡导版权保护的人士艾德·纽顿(Ed Newton-Rex)的观点:一家AI公司要成功,必须具备三样东西——人才、算力、数据。如今一个大模型工程师的年薪可以达到100万到500万美金,而科技公司花在算力上的资金动辄几亿、几十亿、上百亿美元,然后到了同样重要的数据层面,这些公司一分钱都不想花,这公平吗?答案不言而喻。
进一步说,版权的本质是一项公共政策——法律法规怎么写,我们就有什么样的权利。我也一直向版权相关的法律法规制定部门呼吁:要考虑三件事,明确两项原则,找到一条出路。
要考虑的三件事,第一件是“经济”。我们可以算算账:出版、版权行业500多年来对人类的贡献有多大?它已经是我国国民经济的支柱行业之一,中国2024年版权产业占GDP约7.4%。而生成式AI对经济增长的贡献,经研究测算目前还是非常有限的。2024年诺贝尔经济学奖得主达龙·阿西莫格鲁有一篇论文,最终的结论是:生成式AI给人类经济增长带来的贡献少于0.1%。7.4%与0.1%相比,孰重孰轻并不难判断,所以政策首先不能被喧嚣带偏,要先把账算清。
第二件要考虑的事是“文化”。出版、版权行业是文明成果的产出与保护之地。每一轮技术浪潮——报纸、广播、电视、互联网——都冲击过出版,但出版从来没有被抹掉,许多珍贵的文化遗产也正是因此才得到了保存。所以尊重和保护文化应当是我们的底线。
第三件事是“国际”。不同法域路径不同。在AI与版权领域,美国有大量判例在博弈,还没有定论;欧盟在《人工智能法案》里明确了要保护版权,而且要求训练数据透明,要把用过什么数据列出来。在这个背景下,中国作为《伯尔尼公约》等条约的缔约方,如果单方面宣布大模型训练可以随意使用受保护作品而无需授权,那意味着他国主体可以免费用我们的内容,这显然是不合理的。
考虑到这三点问题,我们再来看两项原则:透明和授权。透明就是要告诉社会你用了哪些数据来训练,这也能帮助外部监督,从而减少机器幻觉。授权的起码条件要获得允许。很多权利人并不是“盯着分钱”,他们最大的不满是“未经告知与同意就被用掉了”,知情与署名是对著作权的最基本尊重,这个问题不解决,双方的合作就无从谈起。
展望未来,我认为最后的出路只有一条,那就是合作。像励讯集团这样的公司已经在实际使用生成式AI技术,我们不反对技术;但我们自己做AI产品也会用到别人的内容,那就必须遵循透明与授权的原则,通过合理渠道把内容引进来。
对于出版行业也是一样,建立壁垒,强调你的东西AI公司绝不能碰,肯定不是最终解决方案。我们应该鼓励技术公司和版权权利人合作。现在全球已经有不少案例,我坚信,这条路才是技术与出版行业融合的未来方向。
作者:出版人杂志
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...

